近日,中國科學院北京基因組研究所(國家生物信息中心)國家基因組科學數據中心(CNCB-NGDC)在Genomics,Proteomics & Bioinformatics上,在線發表研究論文The Genome Sequence Archive Family: Toward Explosive Data Growth and Diverse Data Types。GSA數據庫體系接受全世界科研工作者的數據提交,匯交和管理各類型的數據,并對所有公開可用數據提供免費開放訪問,支撐生命科學研究。
組學原始數據歸檔庫(GSA)是生命組學原始測序數據管理的公益性數據庫,旨在推動全球生命組學數據的共享與應用。近年來,隨著組學數據的爆炸性增長和數據類型的多樣化,以及人類遺傳資源數據管理的特殊需求,CNCB-NGDC對GSA數據庫進行了更新和擴展,形成了GSA數據庫體系,包括GSA、GSA-Human和OMIX。
GSA數據庫與2017發布的版本相比,在數據模型、系統功能和數據提交方式等方面進行了更新和功能提升;GSA-Human是存儲人類遺傳資源數據的數據庫,可實現人類遺傳資源數據的受控訪問,保障人類遺傳資源數據的安全性;OMIX數據庫存儲非原始測序數據,如環境組、表型組、代謝組等,作為上述兩種數據資源庫的重要補充,有效地解決了用戶提交除原始測序數據外的其他類型數據的需求。
截至2021年8月14日,GSA和GSA-Human已收集的數據量達9.5 PB,OMIX上線不久數據量已達1.6 TB。GSA數據庫體系已為全球111個國家/地區的用戶提供數據服務,平均每天的數據下載量達4 TB,已成為Elsevier、Wiley、Taylor & Francis 、Cell及Springer Nature出版集團指定的核酸數據歸檔庫,并獲得領域內國內外主流期刊的認可。
研究工作得到國家重點研發計劃、中科院戰略性先導科技專項、中科院信息化專項等的支持,GSA歸檔數據使用的計算機硬件設施得到國家財政部修繕購置專項的支持。
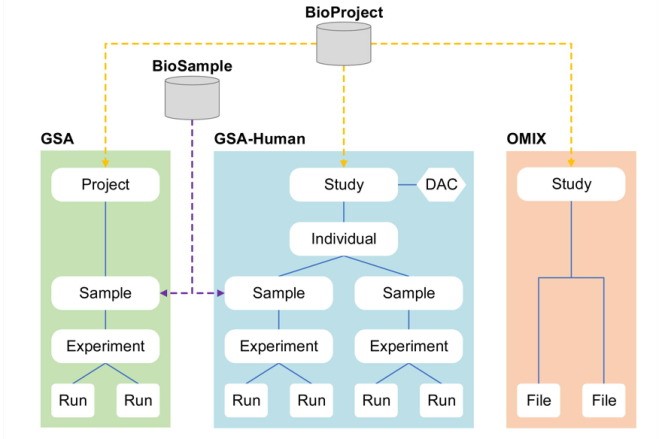
GSA Family數據模型
 官方微信
官方微信

